
If you’re facing an EC2 boot issue after Terraform deployment, you’re not alone. In my recent experience using Rocky Linux 9 on AWS EC2, everything worked perfectly after provisioning — until I rebooted. The instance failed to come back online due to a missing NVMe driver in the initramfs, resulting in a kernel panic. Here’s how I fixed it.
🔍 Symptoms
Since the instance was unreachable after reboot, I went to:
EC2 > Instances > [select instance] > Actions > Monitor and troubleshoot > Get instance screenshot
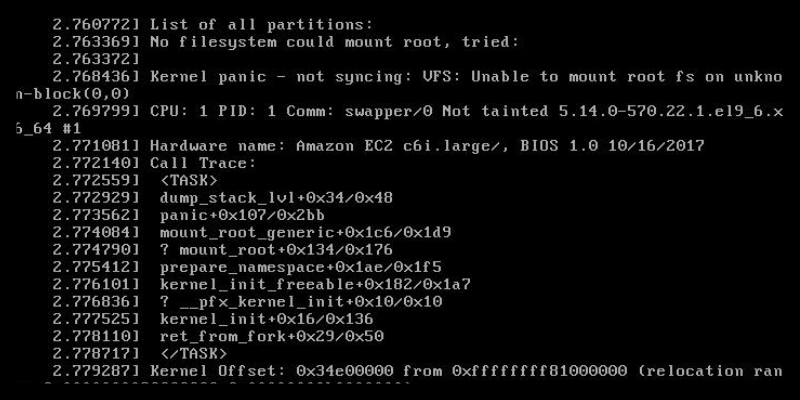
Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0)
This basically means the kernel couldn’t find the root filesystem — which in my case was an NVMe-based EBS volume.
✅ Root Cause
Although the initramfs image already contained the nvme-core and nvme kernel modules, they weren’t being loaded properly during early boot. This is likely because:
- The image was built on a system that didn’t have NVMe hardware at the time
- The initramfs was generated without explicitly including NVMe drivers
- The
hostonlysetting in dracut excluded some modules
🛠️ The Fix
Right after your EC2 instance is deployed and accessible (via SSH), immediately rebuild the initramfs with the correct NVMe drivers, before doing any reboots:
sudo dracut --force --add-drivers "nvme nvme-core"
To confirm it worked, you can inspect the rebuilt initramfs:
lsinitrd /boot/initramfs-$(uname -r).img | grep nvme
You should see output like:
nvme-core.ko.xz nvme.ko.xz
Then reboot and verify that your instance boots cleanly.
💡 Terraform Tip
If you’re automating deployments, consider adding a user-data script or post-deployment Ansible task to rebuild the initramfs as part of the instance provisioning process.
✅ TL;DR
- Problem: EC2 instance won’t boot after first reboot due to NVMe + initramfs issue.
- Solution: Rebuild initramfs with NVMe drivers right after first SSH login.
- Why: AMI may generate initramfs without NVMe support unless forced.